
티스토리 뷰
오늘은 앞서 공부한 Neural Network 개념을 기반으로 두 가지 문제에 대해 실습해보려 합니다!
한 가지는 기존의 방법으로 풀리지 않았던 XOR 문제이고 다른 한 가지는 MNIST숫자 데이터를 분류하는 숫자 분류기입니다.
XOR연산은 다음과 같습니다.

각각의 x와 y데이터를 위와 같이 나타 낼 수 있습니다.
우선 일반적인 접근 방법으로 풀어볼까여?

위 방법은 뉴럴넷을 배우기 전에 사용하던 방식으로 OR나 AND 같은 연산에서 잘 작동하는 모델입니다.
하지만 위 코드를 돌려보면, 정확도가 0.5로 제대로 학습되지 않는 것을 확인해 보실 수 있습니다.

그럼, NN을 적용해 볼까요? 정말 간단한 문제기에 아래와 같이 하나의 레이어만 추가 해주면 됩니다 !ㅎㅎ
Wide하고 Deep 하게 구성할 필요도 없죠! (Wide?? Deep?? 밑에서 설명합니다!)

처음에 두개의 입력을 받아 활성 함수(시그모이드함수)를 거쳐 두 개의 출력이 되는 레이어1을 만든 후
최종 출력 층에 연결해 줍니다. layer1이 다음 행렬 연산의 인자로 들어가게 되기 때문에, 행렬연산 숫자 일치 시키는거에 유의 하세요!

아래와 같이 조금만 코드를 수정해준 후 실행시켜 보면 ...!



아까와는 다르게 cost도 0.02249..로 0에 수렴할정도로 작아진것을 볼 수 있고, 정확도도 1로 잘 학습된 것 을 볼 수 있습니다.
그럼 위에서 잠깐 언급한 Wide와 Deep은 뭘까요?
Wdie 하다는건 한 레이어에서 다른 레이어의 입력으로 들어가는 너비가 커지는 것을 말합니다. 즉 XOR실습을 예로들면 다음과 같이 바꾸는 것이죠.
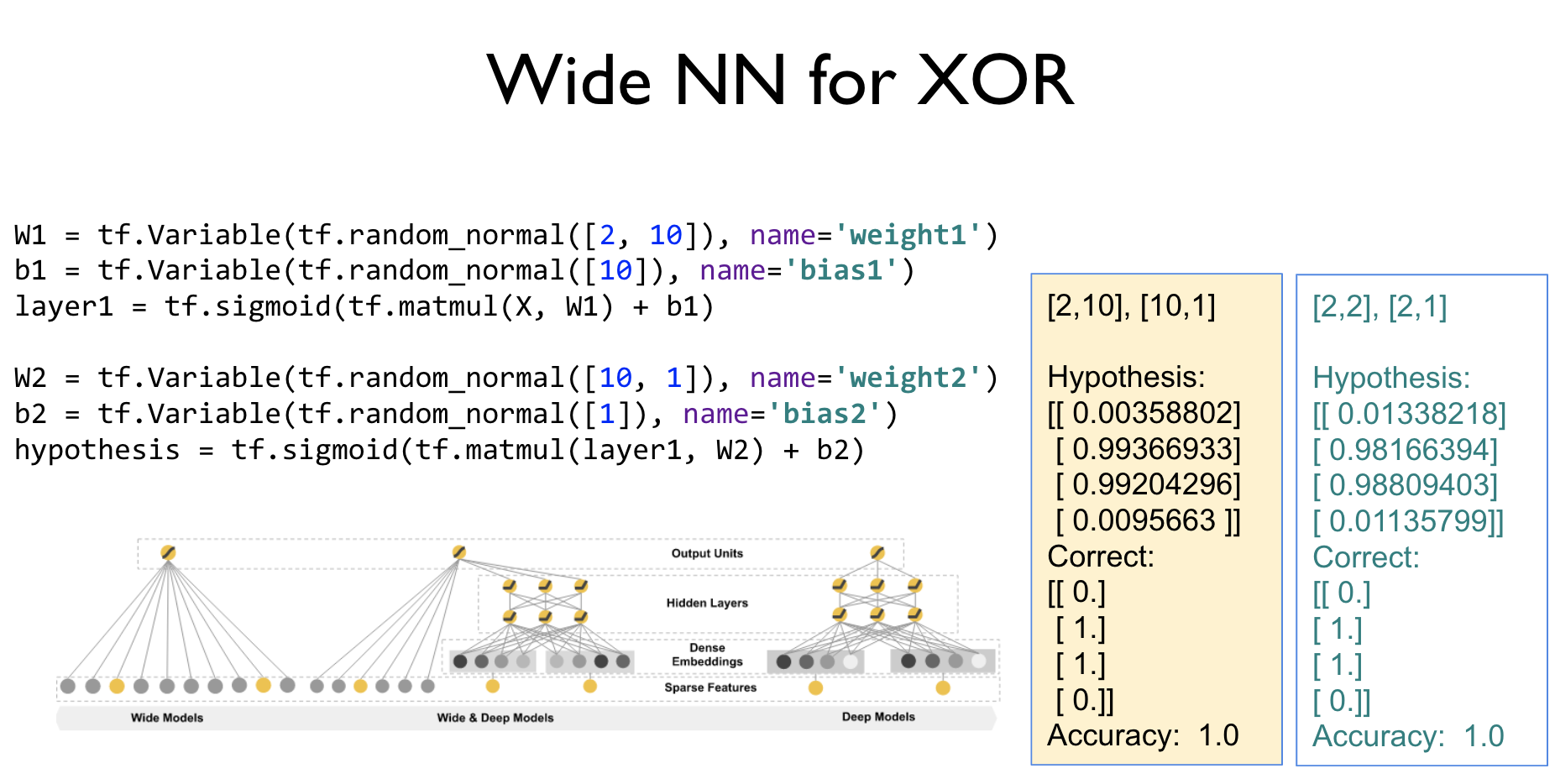
Deep은 예상하셨겠지만, 깊이 즉, 레이어를 여러층으로 많이 쌓는 것 입니다.

실제로 Wdie하거나 Deep하게 만든 후 실행하면 위 두가지 예시처럼, 가설이 기존의 실행코드보다 답안에 더 근접해지는것을 볼 수 있습니다.
이번에는 0~9까지의 손글씨로 작성된 숫자 이미지를 분류하는 모델을 만들어 보려 합니다. 이 이미지 데이터셋을 Mnist data set이라고 하죠.
앞전에 NN개념을 살펴볼 때 activation function 즉, 활성함수로 sigmoid같은 함수 대신 ReLU라는 함수를 사용한다고 했었는데요. 그 이유가 바로 Vanishing gradient에 대처하기 위함입니다.
Back propagation의 경우 미분의 chain rule을 통해 파라미터 값을 조정하게 되는데, sigmoid를 활성 함수로 쓸 경우, layer가 적은 경우(1~2개)는 상관 없지만, layer가 깊어짐에 따라 input layer로 갈수록 output에 얼마나 영향을 끼치는지 알기 어려워져 버립니다. (체인 룰에 의해 1보다 작은 미분 값을 계속 곱해 나가기 때문에 미분 값이 0에 점차 수렴..)

그래서 활성함수로 sigmoid를 사용하지 않고 ReLU를 사용하게 됩니다.
ReLU는 그래프를 보면 알수 있듯이, 0보다 작으면 0, 0보다 크면 선형적으로 커집니다.

따라서 layer간에는 활성 함수로 relu를 사용하여 Vanishing gradient를 방지하고, 마지막 출력 층에만, sigmoid나 softmax를 적용합니다.
자 그럼, 코드를 작성하고 실행해 봅시다!
만약 from tensorflow.examples.tutorials.mnist import input_data 코드 부분에서, 문제가 생긴다면, 아래 포스팅을 통해 해결하시면 됩니다 :)
2020/03/17 - [머신러닝] - TensorFlow, No module named 'tensorflow.examples.tutorials' 문제 해결 방법
TensorFlow, No module named 'tensorflow.examples.tutorials' 문제 해결 방법
No module named 'tensorflow.examples.tutorials' 이 오류는 tutorials폴더가 존재하지 않기 때문에 발생하는 오류인데요. 저는 Mnist 데이터셋을 가져와 실습을 하는 과정에서 맞닥뜨리게 되었습니다 ㅜㅜ 아마..
lsh424.tistory.com

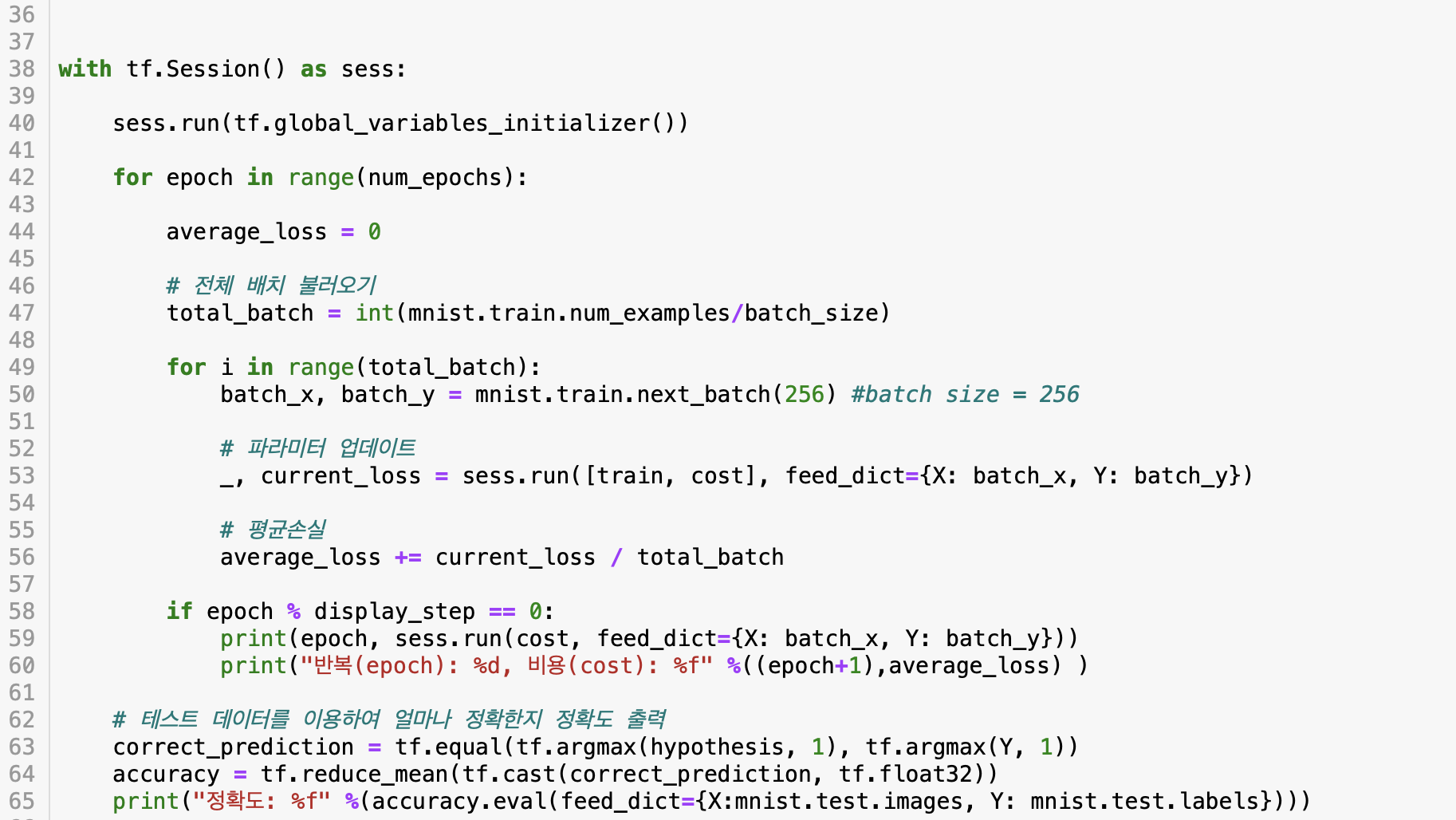
결과는....!?

트레이닝 데이터셋이 아닌 테스트 데이터 셋을 통해 검증을 해보았을 때, 약 94퍼센트로 높은 정확도를 보여주네요! 하지만, 다양한 방법을 통해 97퍼센트 심지어 99퍼센트까지 도달 할 수 있습니다! 이 내용은 다음 포스팅에 이어서 하겠습니다 :)
'머신러닝' 카테고리의 다른 글
| tensorboard를 알아보자 (0) | 2020.03.20 |
|---|---|
| TensorFlow, No module named 'tensorflow.examples.tutorials' 문제 해결 방법 (0) | 2020.03.17 |
| 딥러닝의 본격적인 시작, Neural Network (0) | 2020.03.11 |
| learning rate & overfitting & 학습 데이터.. (2) (0) | 2020.02.25 |
| learning rate & overfitting & 학습 데이터.. (1) (0) | 2020.02.24 |